Note: All code used in this notebook is contained in the notebooks/beaconrunner2050 folder of the Beacon runner repo, and does not use current eth2.0 specs. Most of the content here remains applicable.
TL;DR¶
- We improve upon our second Beacon Runner 2049, an economics-focused simulation environment for eth2.
- Validators are placed on an asynchronous P2P network, with each validator storing their current view of the chain, incoming blocks and attestations in a
Storeobject, as defined in the specs. - Validator behaviours are fully modular and can be plugged into the simulation as long as they follow a simple API, to produce rich agent-based models. Try it yourself!
We want to understand how validator behaviours map to rewards, penalties and chain outcomes. Ideally, validators who are rational are also honest, i.e., they run the eth2 protocol the way it "should" be run. But apart from how incentives are designed, there is no guarantee that this will indeed the case. And as we will see, honesty may not always have a unique instantiation.
In this notebook, we improve upon the first and second Beacon Runners by introducing a more full-fledged simulation environment. If you haven't read the previous two, that's OK! Let's catch up now.
Previously, on...¶
In the first notebook, we introduced the possibility of "wrapping" the current specs in a cadCAD simulation environment. We defined simple strategies for validators that allowed them to produce blocks and attest too. The implementation was centralised in the sense that all validators shared a common view of the chain at all times -- a situation akin to being on a network with perfect information and zero latency.
The natural next step was to relax this assumption, and allow different views of the chain to coexist. In the simplest case, these views have an empty intersection: this is the case when the network is perfectly partitioned, and each side of the partition works independently. We explored in the second notebook how the inactivity leak, which decreases the stake of inactive validators, eventually allows for finalisation to resume. But what if this intersection is not empty? In other words, what if some validators see both sides of the partition? More generally, what if each validator has their own view of the chain, governed by the messages they have received from other validators on the network?
These are the conditions we explore here. They are sufficient to represent a realistic p2p network, where validators receive updates from each other after some (random) delay. We'll reuse the network model introduced in the previous notebook, reintroduced in the next section with a brief introduction to the validator API.
Getting started¶
Once again, we import the specs loaded with a custom configuration file, fast, where epochs are only 4 slots long (for demonstration purposes).
Open code input
import specs
import importlib
from eth2spec.config.config_util import prepare_config
from eth2spec.utils.ssz.ssz_impl import hash_tree_root
prepare_config(".", "fast.yaml")
importlib.reload(specs)
<module 'specs' from '/Users/barnabe/Documents/Research/Projects/beaconrunner/notebooks/beaconrunner2050/specs.py'>
We import our network library, seen in network.py, as well as a library of helper functions for our Beacon Runners, brlib.py. Open them up! The code is not that scary.
Open code input
import network as nt
import brlib
Now on to the new stuff. We've moved honest_attest and honest_propose to a new validatorlib.py file. This file also defines a very important class, the BRValidator, intended to be an abstract superclass to custom validator implementations. BRValidator comes packaged with a Store, a nifty little helper class defined in the specs and a bunch more logic to record past actions and current parameters. We'll get to them in a short while.
We intend BRValidator to be an abstract superclass, meaning that though it is not supposed to be instantiated, it is friendly to inheritance. Subclasses of BRValidator inherit its attributes and methods, and are themselves intended to follow a simple API. Subclasses of BRValidator must expose a propose() and an attest() method which return, respectively, a block or an attestation when queried (or None when they are shy and don't want to return anything yet). We provide an example implementation in ASAPValidator.py, a very nice validator who always proposes and attests as soon as they can, and honestly too.
Open code input
import validatorlib as vlib
from ASAPValidator import *
Let's talk about cadCAD once more. Our simulations are now stochastic, since the latency of the network means that some updates are random. cadCAD makes it easy to organise and run any number of instances as well as define the steps that take place in each instance. But our simulation state is pretty large: there are n validators and for each validator, a certain amount of data to keep track of, including chain states and current unincluded blocks and attestations. So we are using radCAD, a cadCAD extension which supports disabling deep copies of the state at each step, in addition to performance improvements.
We can now import the radCAD classes and methods we'll use here.
Open code input
from radcad import Model, Simulation, Experiment
from radcad.engine import Engine, Backend
import pandas as pd
Are we all set? It seems so!
Discovering the validator and network APIs¶
We'll start slow, as we have done in previous notebooks, before moving to a bigger simulation. We loaded a specs configuration with 4 slots per epoch, so we'll instantiate 4 ASAPValidators, one to attest in each slot.
Genesis¶
First, we obtain a genesis state with 4 deposits registered. Second, we instantiate our validators from this state. A Store is created in each of them that records the genesis state root and a couple other things. Finally we ask our validators to skip the genesis block -- it is a special block at slot 0 that no one is supposed to suggest. The first block from a validator is expected at slot 1.
Open code input
genesis_state = brlib.get_genesis_state(4, seed="riggerati")
validators = [ASAPValidator(genesis_state, i) for i in range(4)]
brlib.skip_genesis_block(validators)
Note that the current store time is exactly SECONDS_PER_SLOT ahead of genesis_time (in our configuration, and the current canonical specs, 12 seconds). We've fast-forwarded beyond the first block at 0 to the start of slot 1.
Open code input
print("Genesis time =", validators[0].store.genesis_time, "seconds")
print("Store time =", validators[0].store.time, "seconds")
print("Current slot =", validators[0].data.slot)
Genesis time = 1578182400 seconds Store time = 1578182412 seconds Current slot = 1
Let's now reuse the network we had in the second notebook. The four validators are arranged along a chain, 0 peering with 1, 1 peering with 2, and 2 peering with 3. We create information sets (who peers with who) to represent the chain.
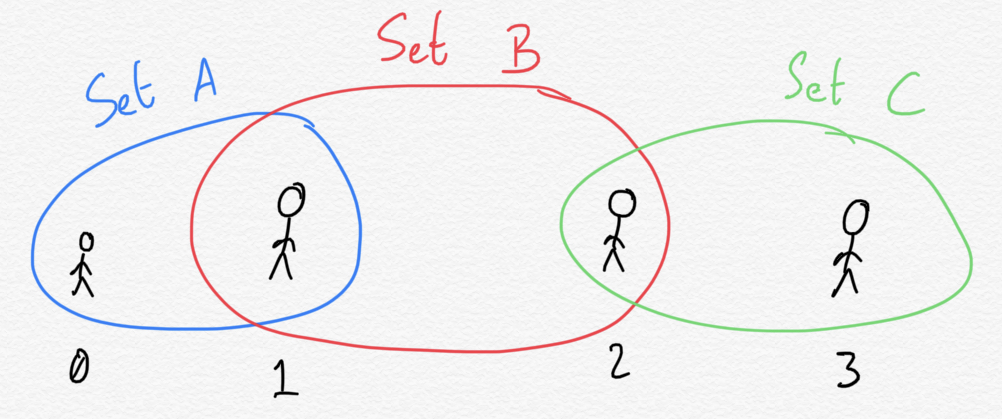
Open code input
set_a = nt.NetworkSet(validators=list([0,1]))
set_b = nt.NetworkSet(validators=list([1,2]))
set_c = nt.NetworkSet(validators=list([2,3]))
net = nt.Network(validators = validators, sets = list([set_a, set_b, set_c]))
Proposer duties¶
When we instantiate new validators, as we have done with ASAPValidator(genesis_state, validator_index), their constructor preloads a few things. First, each validator checks their proposer duties for all slots of the current epoch.
Open code input
proposer_views = [(validator_index, validator.data.current_proposer_duties) \
for validator_index, validator in enumerate(net.validators)]
proposer_views
[(0, [False, False, False, False]), (1, [True, True, False, False]), (2, [False, False, False, True]), (3, [False, False, True, False])]
The array above shows for each validator index (0, 1, 2, 3) whether they are expected to propose a block in either of the 4 slots. Notice that the randomness means the same validator could be called twice in an epoch. This is distinct from attestation duties, where each validator is expected to attest once, and only once, in each epoch.
Since we are at slot 1, we see that validator 1 is expected to propose here. Let's ping them by calling their propose method, which expects a dictionary of "known items": blocks and attestations communicated over the network which may not yet have been included in the chain.
Let's take a brief look at the propose method of the ASAP validator:
def propose(self, known_items) -> Optional[specs.SignedBeaconBlock]:
# Not supposed to propose for current slot
if not self.data.current_proposer_duties[self.data.slot % specs.SLOTS_PER_EPOCH]:
return None
# Already proposed for this slot
if self.data.last_slot_proposed == self.data.slot:
return None
# honest propose
return vlib.honest_propose(self, known_items)
Each validator has a data attribute, its "internals", maintained and updated by the BRValidator class. By exposing the current slot, whether the validator is supposed to propose (in current_proposer_duties) and whether the validator proposed something already (last_slot_proposed), one can build fairly sophisticated strategies already.
Validator 1 is the first to do anything here, so we'll leave the known_items attributes empty.
Open code input
block = net.validators[1].propose({ "attestations": [], "blocks": [] })
print("There are", len(block.message.body.attestations), "attestations in the block")
1 proposes block for slot 1 There are 0 attestations in the block
Unsurprisingly, the new block produced does not contain any attestations.
Now validator 1 communicates its block to the information sets it belongs to. Since it belongs to $\{ 0, 1 \}$ and $\{ 1, 2 \}$, validators 0 and 2 receive the block at this point.
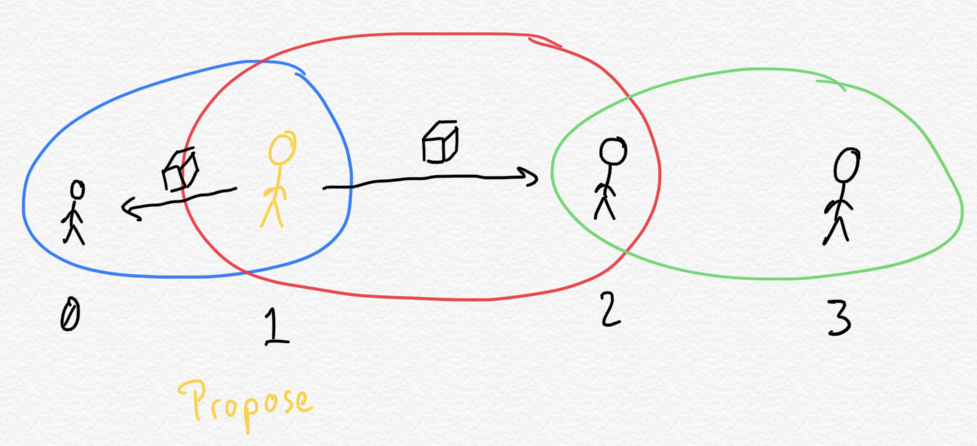
Open code input
nt.disseminate_block(net, 1, block)
In addition to the data attribute, our validators maintain a store which records current beacon chain states. We can access the blocks in those states or the states themselves from the hash of the block. Let's check if validators 0 and 3 have recorded the current block.
Open code input
block_root = hash_tree_root(block.message)
try:
net.validators[0].store.blocks[block_root]
print("0: there is a block")
except KeyError: print("0: no block")
try:
net.validators[3].store.blocks[block_root]
print("3: there is a block")
except KeyError: print("3: no block")
0: there is a block 3: no block
This confirms that validator 3 has not seen the block yet. In the next network update, triggered when update_network is called on the current network object, validator 2 communicates the block to validator 3. But let's not do that just yet, and instead fast-forward a little more to slot number 2.
Open code input
for validator in net.validators:
validator.forward_by(specs.SECONDS_PER_SLOT)
print("Validator 0 says this is slot number", net.validators[0].data.slot)
Validator 0 says this is slot number 2
Attester duties¶
Let's check who is expected to attest at slot 2. Our BRValidator superclass records the slot of the current epoch where validators are expected to attest (their committee slot), in the current_attest_slot attribute of their data. In general, computing attester or proposer duties is expensive, so we try to cache it when we can and recompute it only when necessary.
Open code input
committee_slots = [validator.data.current_attest_slot for validator in net.validators]
pd.DataFrame({ "validator_index": [0, 1, 2, 3], "committee_slot": committee_slots})
| validator_index | committee_slot | |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 2 | 2 | 2 |
| 3 | 3 | 3 |
According to the schedule here, at slot 2, validator 2 is expected to attest. Let's check what items they currently know about.
Open code input
known_items = nt.knowledge_set(net, 2)
print("Validator 2 knows", len(known_items["blocks"]), "block")
print("This block was proposed by validator", known_items["blocks"][0].item.message.proposer_index,
"in slot", known_items["blocks"][0].item.message.slot)
Validator 2 knows 1 block This block was proposed by validator 1 in slot 1
Validator 2 knows about the block that validator 1 sent in slot 1! All is well here. Validator 2's attestation will set this block as the current head of the chain and the heat goes on.
Open code input
attestation = net.validators[2].attest(known_items)
print(attestation)
None
Woah, what happened here? Validator 2 refused to attest.
Let's back up a bit and see why. Validator 2 is expected to attest during slot 2. Honest validators however are supposed to leave a bit of time for block proposers to communicate their blocks. We are indeed in slot 2, but we are early into it, at the very start. Meanwhile, slots last for about 12 seconds and validators are only expected to attest a third of the way into the slot, i.e., 4 seconds in. This leaves 4 seconds for the block proposer of slot 2 to produce their block and communicate it (in reality, a bit more since producers can start producing before the end of the previous slot, at the risk of missing incoming attestations).
We can also look at the attest code in ASAPValidator to see this:
def attest(self, known_items) -> Optional[specs.Attestation]:
# Not the moment to attest
if self.data.current_attest_slot != self.data.slot:
return None
# Too early in the slot
if (self.store.time - self.store.genesis_time) % specs.SECONDS_PER_SLOT < 4:
return None
# Already attested for this slot
if self.data.last_slot_attested == self.data.slot:
return None
# honest attest
return vlib.honest_attest(self, known_items)
Alright. Let's assume that no one wants to propose anything yet for this slot. We'll forward everyone by 4 seconds and see if validator 2 is ready to attest then.
Open code input
for validator in net.validators:
validator.forward_by(4)
Open code input
print("Validator 2 says this is slot number", net.validators[2].data.slot)
print("Time is now", net.validators[2].store.time)
print("We are now",
(net.validators[2].store.time - net.validators[2].store.genesis_time) % specs.SECONDS_PER_SLOT, "seconds into the slot")
Validator 2 says this is slot number 2 Time is now 1578182428 We are now 4 seconds into the slot
Ready to attest now?
Open code input
attestation = net.validators[2].attest(known_items)
print(attestation)
Attestation(Container)
aggregation_bits: SpecialBitlistView = Bitlist[2048](1 bits: 1)
data: AttestationData = AttestationData(Container)
slot: Slot = 2
index: CommitteeIndex = 0
beacon_block_root: Root = 0x204c3c90f89e27ef085dfbd38e81c07036e637d4742d5d76705a6133243204b3
source: Checkpoint = Checkpoint(Container)
epoch: Epoch = 0
root: Root = 0x0000000000000000000000000000000000000000000000000000000000000000
target: Checkpoint = Checkpoint(Container)
epoch: Epoch = 0
root: Root = 0x838fb6c5f9b6e8ae5005b16fed7da017452a8bd9d7ed2eda6434b69db123485c
signature: BLSSignature = 0x000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
Yes! Validator 2 returned a well-formed attestation. ASAP validators are in a hurry, sure, but not in such a hurry that they would attest too early in the slot.
What are the dangers of attesting too early? Simply put, validators are rewarded for attesting to the correct head of the chain from the perspective of their committee slot. Suppose a validator is expected to attest for slot 2. They send their attestation out before receiving the block for slot 2. In their attestation, they attested for the head of the chain they knew about, i.e., the block at slot 1. Later on, the block for slot 2 is included in the canonical chain. The head in the attestation is now incorrect!
But shouldn't a validator attest as late as possible then? We are dipping our toes in the waters of game theory here. I like it. Maybe! Though attesting too late means that the reward obtained for being included early decreases, and if you are really too late, like an epoch late, then you cannot be included at all. So pick your poison here.
We'll define (or you can try it yourself!) a different validator behaviour, attesting as soon as a block is received in the slot, or slightly before the end of the slot if no block comes in. This is much unlike the current validator, who attests four seconds in no matter what. Let's look at this in a different notebook!
We need to forward a bit more for validators to record the new attestation. By default, validators ignore incoming attestations for the slot they are currently in. This is because an attestation for slot 2 can at the earliest be included in a block for slot 3. So let's jump to slot 3 by forwarding by 8 seconds.
Open code input
for validator in net.validators:
validator.forward_by(8)
print("Validator 2 says this is slot number", net.validators[2].data.slot)
Validator 2 says this is slot number 3
Let's have validator 2 disseminate their attestation. In the next section we'll see how other validators react to it.
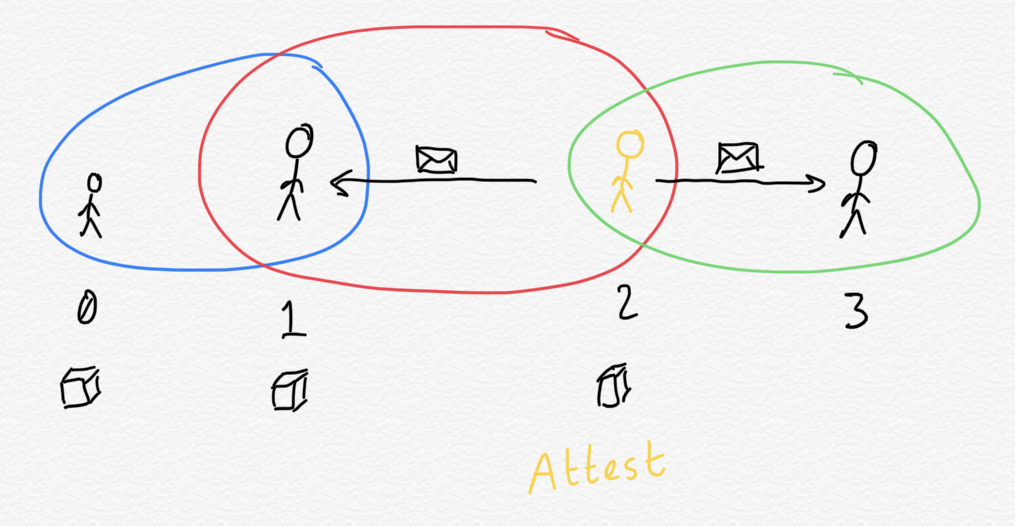
Open code input
nt.disseminate_attestations(net, [(2, attestation)])
Final state¶
We'll check the state of each validator in turn. The store records in its latest_messages attribute the latest message received from every other validator (message being "attestation" here). This is the LMD of LMD-GHOST, Latest Message-Driven fork choice!
Open code input
print(net.validators[0].store.latest_messages)
{}
Validator 0 has an empty latest_messages attribute. Remember that validator 0 is not peering with validator 2. Since the network was not updated, the recent attestation from validator 2 did not make its way to validator 0.
Open code input
print(net.validators[1].store.latest_messages)
{2: LatestMessage(epoch=0, root=0x204c3c90f89e27ef085dfbd38e81c07036e637d4742d5d76705a6133243204b3)}
Validator 1 has seen the attestation from validator 2, since they are peering together. This makes sense.
Open code input
print(net.validators[2].store.latest_messages)
{2: LatestMessage(epoch=0, root=0x204c3c90f89e27ef085dfbd38e81c07036e637d4742d5d76705a6133243204b3)}
Obviously, validator 2 also knows about its own attestation.
Open code input
print(net.validators[3].store.latest_messages)
{}
Hmm, this is trickier. Validator 3 received validator 2's attestation, since they are peering together. But why isn't it showing here in the latest_messages?
The reason is simple: validator 2's attestation vouches for validator 1's block as the current head of the chain. But validator 3 doesn't yet know about this block! From the point of view of validator 3, the attestation might as well be vouching for an nonexistent head. In our net object, the attestation is recorded as "known" by validator 3, but it cannot participate in validator 3's fork choice, until validator 3 knows about validator 1's block.
Now that we have some intuition for what’s going on behind the scenes, let’s take a look at a larger-scale simulation!
Simulating a complete chain¶
First up, we need to reload our libraries as we'll be using a different specs configuration; the medium config now has 16 slots per epoch (see the second notebook where we used the same configuration).
Open code input
prepare_config(".", "medium.yaml")
importlib.reload(specs)
importlib.reload(nt)
importlib.reload(brlib)
importlib.reload(vlib)
from ASAPValidator import *
We'll start with 100 validators, divided into two sets, with a small overlap.
Open code input
num_validators = 100
genesis_state = brlib.get_genesis_state(num_validators)
validators = [ASAPValidator(genesis_state.copy(), validator_index) for validator_index in range(num_validators)]
brlib.skip_genesis_block(validators)
set_a = nt.NetworkSet(validators=list(range(0, int(num_validators * 2 / 3.0))))
set_b = nt.NetworkSet(validators=list(range(int(num_validators / 2.0), num_validators)))
network = nt.Network(validators = validators, sets=list([set_a, set_b]))
print("Set A = ", set_a)
print("Set B = ", set_b)
Set A = NetworkSet(validators=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65]) Set B = NetworkSet(validators=[50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99])
Notice that validators 50 to 65 belong to both sets. If the intersection was completely empty, we'd be back to the partition case we saw in the previous notebook.
Same as before, we set our initial_conditions to only contain the network object we just defined.
Open code input
initial_conditions = {
'network': network
}
How does the simulation proceed? We change the rules significantly here. In previous notebooks, we kept the pattern one simulation step = one slot. But to model the effects of network latency or timeliness of validator moves, this is not fine-grained enough. A frequency parameter (in Hertz) controls how many times per second we update the simulation.
Here is what happens at each update:
- (Policy) All validators are queried to check if they want to attest at this time.
- (State update) If attestations were made, we disseminate them over the network.
- (Policy) All validators are queried to check if they want to propose a block at this time.
- (State update) If blocks were proposed, we disseminate them over the network.
- (State update) We call
tickto move the clock by one step (= a second iffrequencyis 1, a tenth of a second iffrequencyis 10 etc). Whentickmoves the clock past the start of a new slot, validators update their internals, checking for instance their new attester or proposer duties if this tick coincides with a new epoch.
Whenever tick is called, we also check whether we want the network to update or not, by flipping a biased coin. By "updating the network", we mean "peers exchange messages". In the chain example above, with 4 validators arranged as 0 <-> 1 <-> 2 <-> 3, it takes two network updates for a message from validator 3 to reach validator 0 (when validator 3 sends their message, we assume that it reaches all their peers instantly).
The update frequency of the network is represented by the network_update_rate simulation parameter, also in Hertz. A network_update_rate of 1 means that messages spread one step further on the network each second.
Open code input
params = {
"frequency": [1],
"network_update_rate": [1]
}
As usual, we have our partial state update blocks which represent the substep in the simulation steps.
Open code input
psubs = [
{
'policies': {
'action': brlib.attest_policy # step 1
},
'variables': {
'network': brlib.disseminate_attestations # step 2
}
},
{
'policies': {
'action': brlib.propose_policy # step 3
},
'variables': {
'network': brlib.disseminate_blocks # step 4
}
},
{
'policies': {
},
'variables': {
'network': brlib.tick # step 5
}
},
]
We'll now set the parameters for our run. We want to run it for number_slots, meaning that we need steps timesteps, as given by the formula below. Notice that we feed our parameters dictionary to the M key of simulation_parameters. This exposes the frequency and network_update_rate parameters to all state update functions in our simulation (here we only use it for tick, which updates the clock of all validators and potentially the network too).
Open code input
number_epochs = 6
number_slots = number_epochs * specs.SLOTS_PER_EPOCH
steps = number_slots * specs.SECONDS_PER_SLOT * params["frequency"][0]
print("will simulate", number_epochs, "epochs (", number_slots, "slots ) at frequency", vlib.frequency, "moves/second")
print("total", steps, "simulation steps")
will simulate 6 epochs ( 96 slots ) at frequency 1 moves/second total 1152 simulation steps
One last thing: we discussed before the use of a cadCAD fork that doesn't record a complete copy of the simulation state at each step. This is critical because when we set a very high frequency, during many steps nothing really happens: no one is proposing or attesting, but we still should ping validators to check if they want to do either. Recording the full state every step is quite wasteful! So instead, we'll define observers, or metrics: functions of the state that record a simple value at each step, such as the average balance of validators or the current slot. Let's write an observer for the current slot first:
Open code input
current_slot = lambda s: s["network"].validators[0].data.slot
That was quite easy. Our state only includes the network object and since we assume all validators share a clock (or at least they are all synced to the same time) any validator's current slot will do.
Now let's think about how to get the average balance. Of course, this depends on which beacon chain state we are looking at. Each validator maintains their own current state, which is made up of all the blocks and attestations they have seen until now. All validators may not agree on the current balances of everyone! In the extreme case of a partition, which we discussed in the previous notebook, the two sides of the partition had completely different accounts of the current distribution.

There is no one single correct answer. If we believe our network is fully connected (i.e., no partition) with reasonable latency, it follows that all validators eventually receive any given message in a reasonable amount of time. Under these assumptions, to get a good idea of the distribution (of average balances) over all validators, it's probably enough to sample the distribution of any one validator.
Open code input
from eth2 import gwei_to_eth
def average_balance(state):
validator = state["network"].validators[0]
head = specs.get_head(validator.store)
current_state = validator.store.block_states[head]
current_epoch = specs.get_current_epoch(current_state)
number_validators = len(current_state.balances)
return gwei_to_eth(float(sum(current_state.balances)) / float(number_validators))
We now have a couple of custom functions to add our two observers, current_slot and average_balance, to the simulation proceedings. In the background, we record the current slot and the average balance in the state of the simulation, so we need to add them to the initial conditions as well as to the state update blocks defined above.
Open code input
from cadCADsupSUP import *
observers = {
"current_slot": current_slot,
"average_balance": average_balance
}
observed_ic = get_observed_initial_conditions(initial_conditions, observers)
observed_psubs = get_observed_psubs(psubs, observers)
Let's run it!
Open code input
%%capture
model = Model(
initial_state=observed_ic,
state_update_blocks=observed_psubs,
params=params,
)
simulation = Simulation(model=model, timesteps=steps, runs=1)
experiment = Experiment([simulation])
experiment.engine = Engine(deepcopy=False, backend=Backend.SINGLE_PROCESS)
result = experiment.run()
df = pd.DataFrame(result)
This takes a little time (despite a lot of caching behind the scenes), but executes and returns a simulation transcript with our observers, in df.
Open code input
df.head()
| network | current_slot | average_balance | simulation | subset | run | substep | timestep | |
|---|---|---|---|---|---|---|---|---|
| 0 | Network(validators=[<ASAPValidator.ASAPValidat... | 1 | 32.0 | 0 | 0 | 1 | 0 | 0 |
| 1 | Network(validators=[<ASAPValidator.ASAPValidat... | 1 | 32.0 | 0 | 0 | 1 | 1 | 1 |
| 2 | Network(validators=[<ASAPValidator.ASAPValidat... | 1 | 32.0 | 0 | 0 | 1 | 2 | 1 |
| 3 | Network(validators=[<ASAPValidator.ASAPValidat... | 1 | 32.0 | 0 | 0 | 1 | 3 | 1 |
| 4 | Network(validators=[<ASAPValidator.ASAPValidat... | 1 | 32.0 | 0 | 0 | 1 | 1 | 2 |
Let's plot the average balance over time, taking slots as our time unit.
Open code input
df.plot("current_slot", "average_balance")
<AxesSubplot:xlabel='current_slot'>

It increases! Remember that our epochs are 16 slots long here. Validators are behaving well, the network latency is small enough that no message is delayed too much, it's all good!
Arrival¶
So what have we done here?
- We have a group of validators who are all individually keeping track of their view of the beacon state.
- Validators are on a network and communicate with each other, keeping track of known (but perhaps unincluded) attestations and blocks.
- Whenever something changes, e.g., the beginning of a new slot/epoch or a new block/attestation received on-the-wire (as in, from the p2p network), validators update their internals to parameterise their strategies.
- Each step, the simulation pings all validators and asks whether they want to propose or attest at this point in time. Based on their current data and past actions, they either return a block and/or an attestation, or nothing.
Now that we have this nice playground for validators to roam around, we are getting close to a full-fledged agent-based model. But we need more agents! Who expects here that all validators will be ASAP always? And is ASAP the only "good" behaviour? Probably not!
We'll use the framework developed in this notebook to explore these questions, with a series of smaller "case studies" looking at specific questions. Note that our simulation environment is still incomplete: validators should do more than just proposing and attesting.
- Up until now we assumed proposers were taking on the responsibility of aggregating their known attestations to record them in their proposed blocks. In eth2, aggregators are functionally different, and are validators chosen randomly for each slot.
- We also haven't given our validators the power to slash malicious validators. With a few tweaks here and there we can do that simply enough.